안녕하세요. 위기의 코딩맨입니다.
오늘은 전 포스팅에 소개드렸던 캐글에서 타이타닉 생존률 분석의 튜토리얼을 진행해 보도록 하겠습니다.
개발을 시작할 때, Hello World를 가장 먼저 시작하는 부분이 Titanic Tutorial이라고 생각하시면 됩니다.
먼저, 캐글에 대해서 궁금하시면 전 포스팅을 참고해주세요!
[Kaggle] Kaggle이란 무엇인가?!
안녕하세요. 위기의 코딩맨입니다. 요즘 데이터를 활용한 AI 플랫폼들이 많이 제작되고 활성화가 되고있습니다. 그 중, 데이터를 참고해서 예측, 분석하는 플랫폼인 캐글(kaggle)에 대해서 간단하
we-co.tistory.com
[ Titanic Tutorial ]
해당 타이타닉 튜토리얼은
경쟁에 대한 설명, 데이터를 분석 및 출력하고, 제출하는 크게 3가지 파트로 나뉘게 됩니다.
소스를 보며 간단하게 진행해 보도록 하겠습니다.
Part.1
파트 1에서는 경쟁에 참가하는 방법에 대해서 설명해 주고 있습니다.
기업, 단체에서 올린 항목에서 Join Competition을 클릭하여 경쟁에 참여하라며 설명합니다.
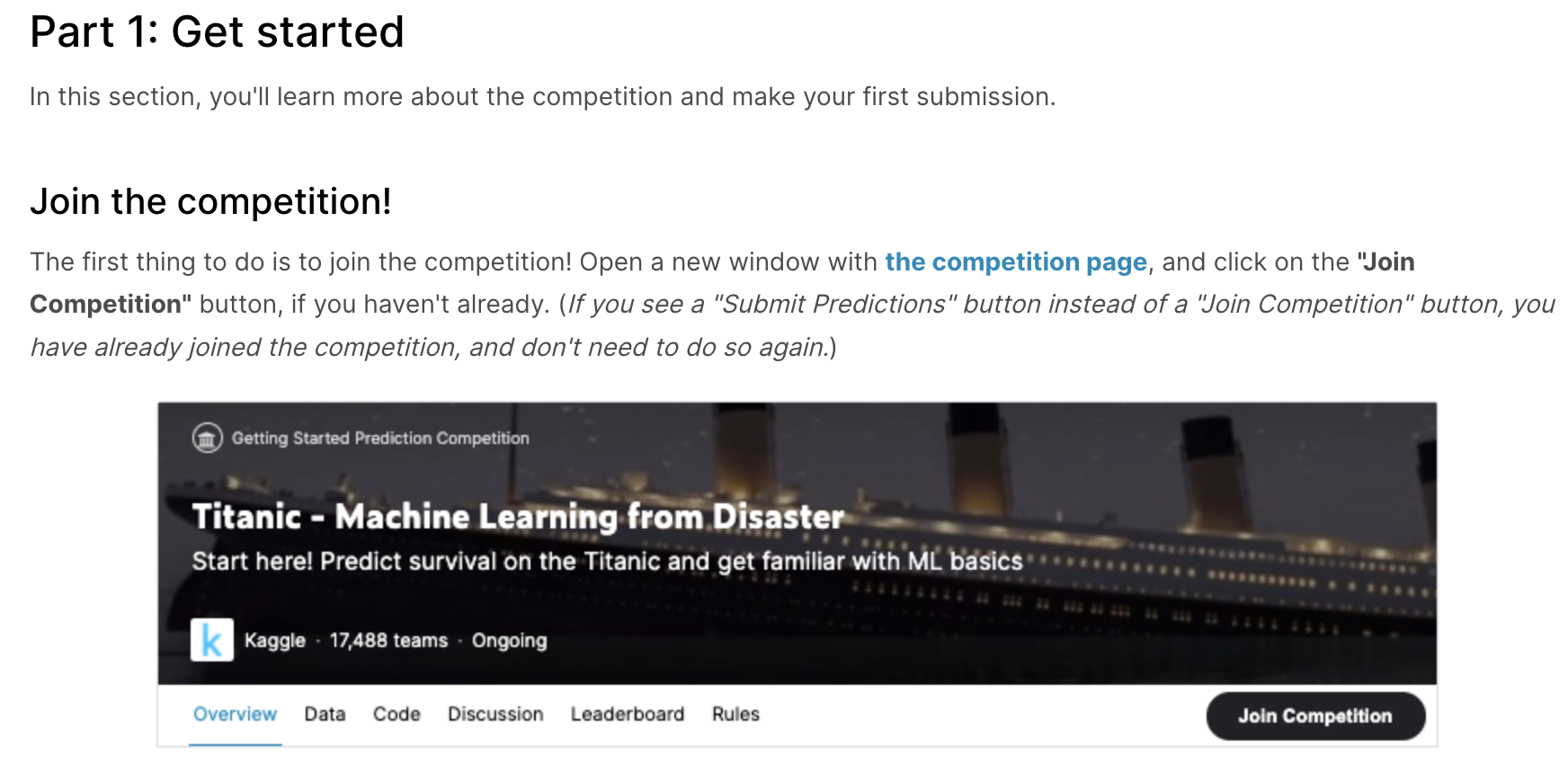
그리고 해당 튜토리얼에서 원하는 주제를 설명하고 있습니다.
name, age, price of ticket, etc를 활용하여 생존률을 분석해야합니다.
데이터는 train.csv, test.csv, gender_submission.csv 3가지를 사용하게됩니다.

데이터에 대해서 간단하게 설명드리면,
train.csv의 데이터에는 탑승 승객의 891명의 세부 정보의 데이터이며, 해당 데이터를 분석하여 패턴을 찾아야합니다!
test.csv 데이터는 train.csv에서 분석하여 얻은 패턴을 test.csv에 적용하여 분석한 결과가 잘 분석 되었는지 확인할 수 있습니다.
gender_submission.csv의 데이터는 예측을 구성하는 방법을 보여주는 데이터입니다.
주로 train.csv, test.csv를 활용하게 됩니다.
part.2
파트 2부분에서는 직접 코드를 입력하면서 진행하게 됩니다.
먼저, 튜토리얼에서 코드 작성을 위한 Notebook을 제공해줍니다.
New Notebook을 클릭 후, 로그인 후 진행하시면 됩니다.

그럼 이렇게 기본적인 라이브러리와 사용되는 파일이 적용되어 있는 것을 확인하실수 있습니다.

다음 단계로 해당 train.csv와 test.csv의 데이터를 간단하게 확인하는 단계의 코드를 작성합니다.

위에서 언급했듯이 train 데이터는 891개, 테스트를 진행하기 위한 데이터는 418개로 확인 됩니다.

데이터는 확인이 되었으니 이제 패턴을 찾을 차례입니다.
처음에는 어떻게 진행해야 할지 모르니 튜토리얼을 따라가 봅시다!
gender_submission.csv 데이터에서는 모든 여성 승객이 생존하고,
모든 남자가 사망했다고 가정했다고 합니다.
이건 예측을 했다고 보기 어렵겠죠??
이것이 맞게 추측 되었는지 train.csv 데이터로 확인해보도록 하겠습니다.
여성은 총 314명 중, 233명 생존 약 74%
남성은 총 577명 중, 109명 생존 약 19%

결과론 적으론 gender_submission.csv은 좋지 않은 예측으로 판단됩니다.
해당 튜토리얼에서는 랜덤 포레스트 모델을 간단하게 제작하여 예측을 진행합니다.
해당 모델에서는 Class, Sex, SibSp, Parch의 데이터를 통해서 패턴을 찾는다고 합니다.
train.csv의 패턴을 기반으로 트리를 구성하고, test.csv의 승객에 대한 예측을 진행합니다.
해당 예측은 submission.csv 파일로 저장되도록 코드를 작성했다고 합니다.
램덤 포레스트 모델을 사용하기 위해 사이킷런을 가져와서 적용합니다.
그리고 데이터를 pd를 통해 변환합니다.

n_estimators는 트리의 개수를 지정하는 항목입니다. 튜토리얼에서는 100개의 의사결정트리로 구성됩니다.
max_depth는 해당 트리의 최대 깊이를 나타냅니다. 현재는 5로 최대 높이로 설정되어있습니다.
random_state는 랜덤 시드를 설정합니다.
model.fit은 모델을 위한 훈련 데이터를 적용합니다.
위에서 선언한 X, y 데이터를 모델에 적용합니다.

생성된 submission.csv를 확인해보면
test.csv의 데이터의 사람이 생존했는지 여부를 모델을 통해 결과가 나온 것을 확인할 수 있습니다.

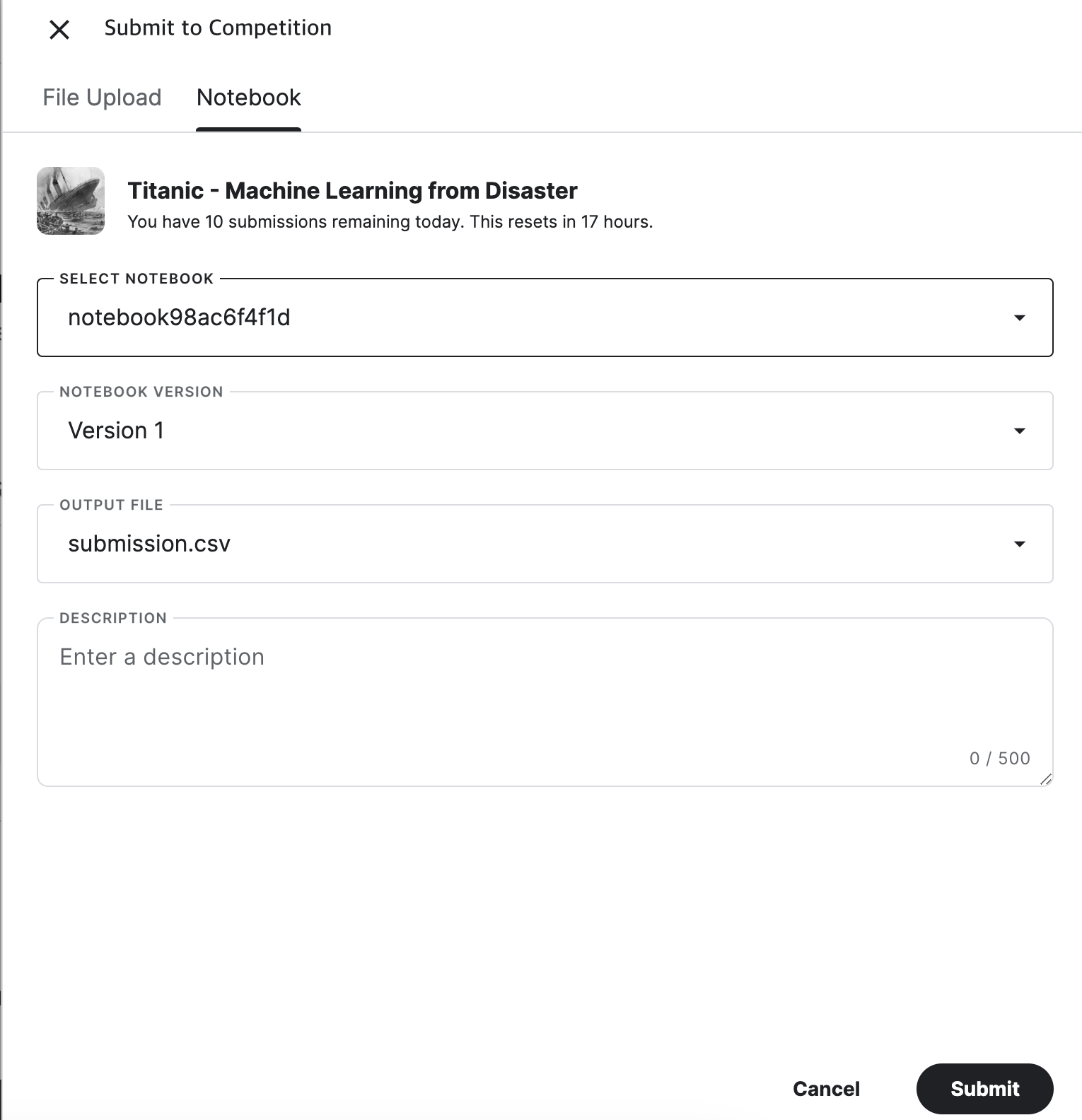
저장 방법은 Save Version을 선택하시고

기존 타이타닉 항목에 submit Prediction을 클릭하시고

위의 Notebook 항목을 선택하시고
생성했던 버전을 선택하고 파일을 선택하고 제출하시면 됩니다.
오늘은 조금 길었지만 캐글의 hello world! 타이타닉 생존율 분석을 진행해 보았습니다.
앞으로 집 값 분석과 튜토리얼이 아닌 다른 분석 코드를 분석해보고, 직접 분석을 진행해보겠습니다.

'Python > Kaggle' 카테고리의 다른 글
| [Kaggle] 집 값을 예측해보자- House Prices - Advanced Regression Techniques[2] (3) | 2023.12.28 |
|---|---|
| [Kaggle] 집 값을 예측해보자- House Prices - Advanced Regression Techniques[1] (5) | 2023.12.27 |
| [Kaggle] Kaggle이란 무엇인가?! (3) | 2023.12.11 |


