안녕하세요. 위기의 코딩맨입니다.
오늘은 이어서 캐글의 대표적인 문제 집값 예측하기를 진행해보도록 하겠습니다.

캐글에 대해서 궁금하신 분들은
아래 포스팅을 참고해주세요!
[Kaggle] Kaggle이란 무엇인가?!
안녕하세요. 위기의 코딩맨입니다. 요즘 데이터를 활용한 AI 플랫폼들이 많이 제작되고 활성화가 되고있습니다. 그 중, 데이터를 참고해서 예측, 분석하는 플랫폼인 캐글(kaggle)에 대해서 간단하
we-co.tistory.com
이번에는 집 값에서 가장 많이 참조된 Comprehensive data exploration with Python을 분석해보며 Kaggle과 친해져 봅시다!
좋아요를 13942개, Copy & Editd을 무려 2만4천개 가량 받은 NoteBook입니다.

[ Comprehensive data exploration with Python ]
해당 NoteBook의 기본적인 단계는 5단계로 이루어져 있습니다.
천천히 단계별로 진행해보도록 하겠습니다.
일단 해당 경쟁의 노트북을 생성해서 데이터를 확인해봅시다!

지금은 기본 환경이고, 사용하기 위한 라이브러리를 불러와 줘야합니다.

추가적으로 사용되는 라이브러리를 확인해봅시다.
matplotlib.pyplot - Python에서 사용되는 2D 그래픽을 생성하는 라이브러리로 생각하시면 됩니다.
seaborn - 통계적 데이터를 시각화하는 Python 라이브러리입니다.
scipy.stats.norm - 기술연산 라이브러리입니다. 정규분포 등 통계적인 함수를 제공합니다.
sklearn.preprocessing import StandardScaler - 사이킷런은 머신러닝 라이브러리로 StandardScaler는 데이터의 특성을 표준화하는데 사용됩니다.
scipy - 다양한 통계적 도구를 제공하는 라이브러리입니다.
warnings - Python의 경고 메시지를 관리하는 내장 라이브러리로 특정된 경고를 무시할 수 있습니다.
%matplotlib inline - Kaggle이 Jupyter NoteBook 환경인데 해당 환경에서 그래프를 인라인으로 표시되도록 지정하는 명령어입니다.
해당 데이터가 맞게 들어왔는지 확인해봅니다!

데이터를 확인하고
이제 파트1이 시작됩니다.
Part.1
What can we expect?
무엇을 기대할 수 있을까? 의 질문으로 시작됩니다.
데이터를 통해 건물, 공간, 위치를 정의할 수 있다고 얘기하고 있습니다.
건물과 관련된 변수는 OverallQual, 공간은 TotalBsmtSF, 위치는 Neighborhood의 데이터를 참고하면 된다고합니다.
여기서 중요한점!
나중에 이런 가이드가 없을 때, 이런 데이터를 가지고 분석을 해야된다고하면 데이터와 유추할수 있는 정보의
연관성을 빠르게 가져올 수 있는 능력을 키워야 할것같다는 생각이 듭니다.
해당 글에서도 변수와의 연관성을 찾는 연습이 중요하다고 합니다.
변수와 변수와의 연관성을 설명하며 par.1은 종료되고, part.2가 시작됩니다.
Part.2
판매 가격(SalePrice)을 분석해보자!
1460개의 데이터이며
mean(평균값), std(표준편차), min(최저), 25%~75%, max(최고값) 을 나타내고 있습니다.

해당 데이터를 히스토그램으로 표현해보기도 합니다.
대체적으로 100000~250000정도에 모여있는것을 확인할 수 있습니다.
해당 데이터는 정규 분포의 형태를 가지고 있지 않고 비대칭 분포를갖고있는것을 확인할 수 있습니다.
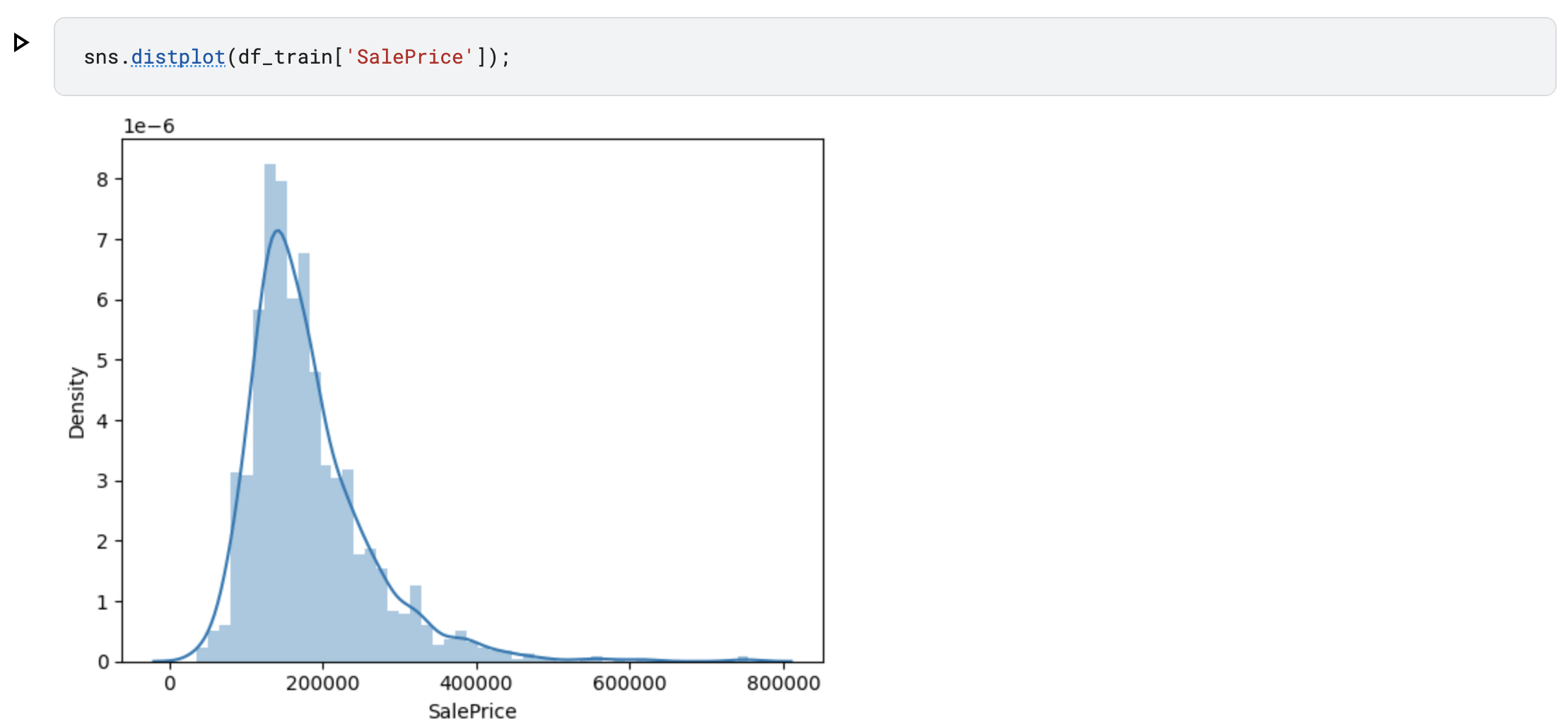
다음으로 왜도와 첨도를 나타내고있습니다.
왜도(Skewness)는 분포의 기울기를 나타낸가고 생각하시면됩니다. 0보다 크면 오른쪽, 0보다 작으면 왼쪽으로 긴 분포를 가집니다.
첨도(Kurtosis)는 뾰족한 부분을 나타냅니다. 정규 분포의 첨도는 3을 나타내고, 3보다 크면 뾰족해지고 3보다 작으면 둥근 분포를 갖게됩니다.
해당 데이터의 왜도는 1.88..., 첨도는 6.53...을 타나내고 있는것을 확인할 수 있습니다.

그리고 위에서 언급했듯이 변수와 변수간의 관계를 살펴보도록 하겠습니다.
GrLivArea, TotalBsmtSF와 SalePrice의관계를 시각화하여 나타내고 있습니다.
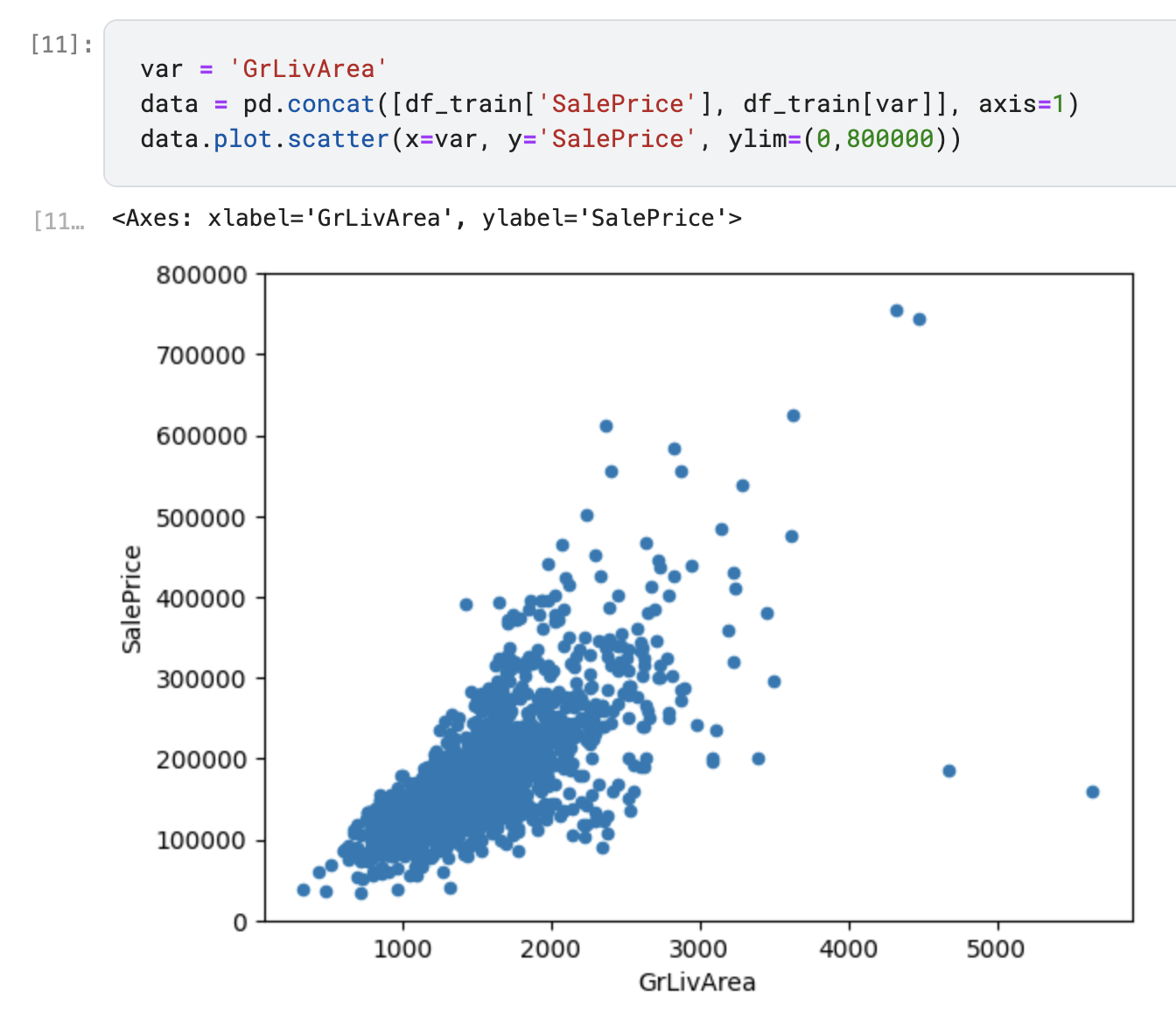 |
 |
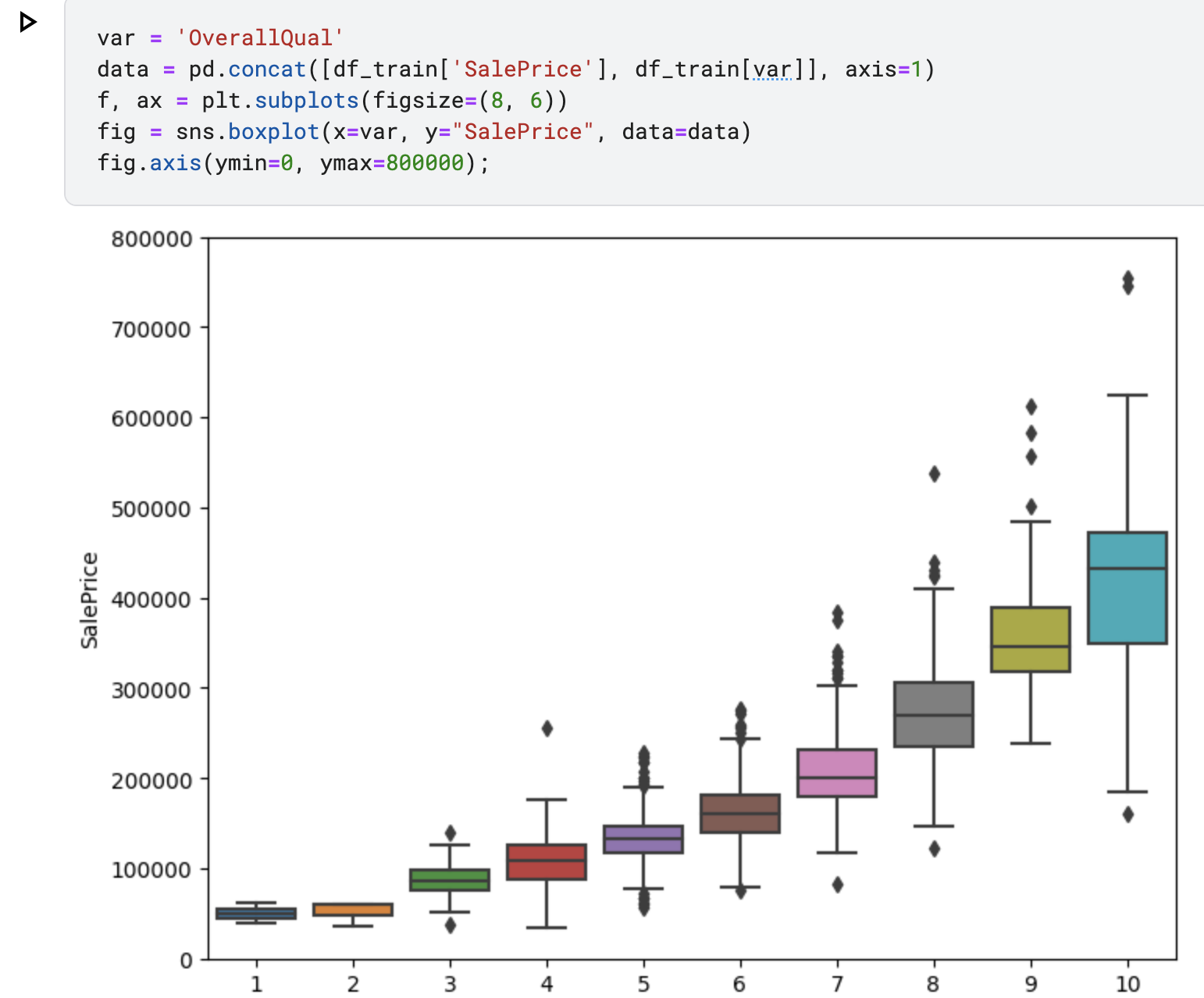
pd의 concat함수로 SalePrice와 OverallQual의 데이터를 합치고
seaborn를 사용하여 boxplot을 통해 데이터의 관계를 시각화 하고있습니다.
axis(ymin=0,ymax=800000)는 Y축의 최저, 최고 값의 범위를 설정합니다.
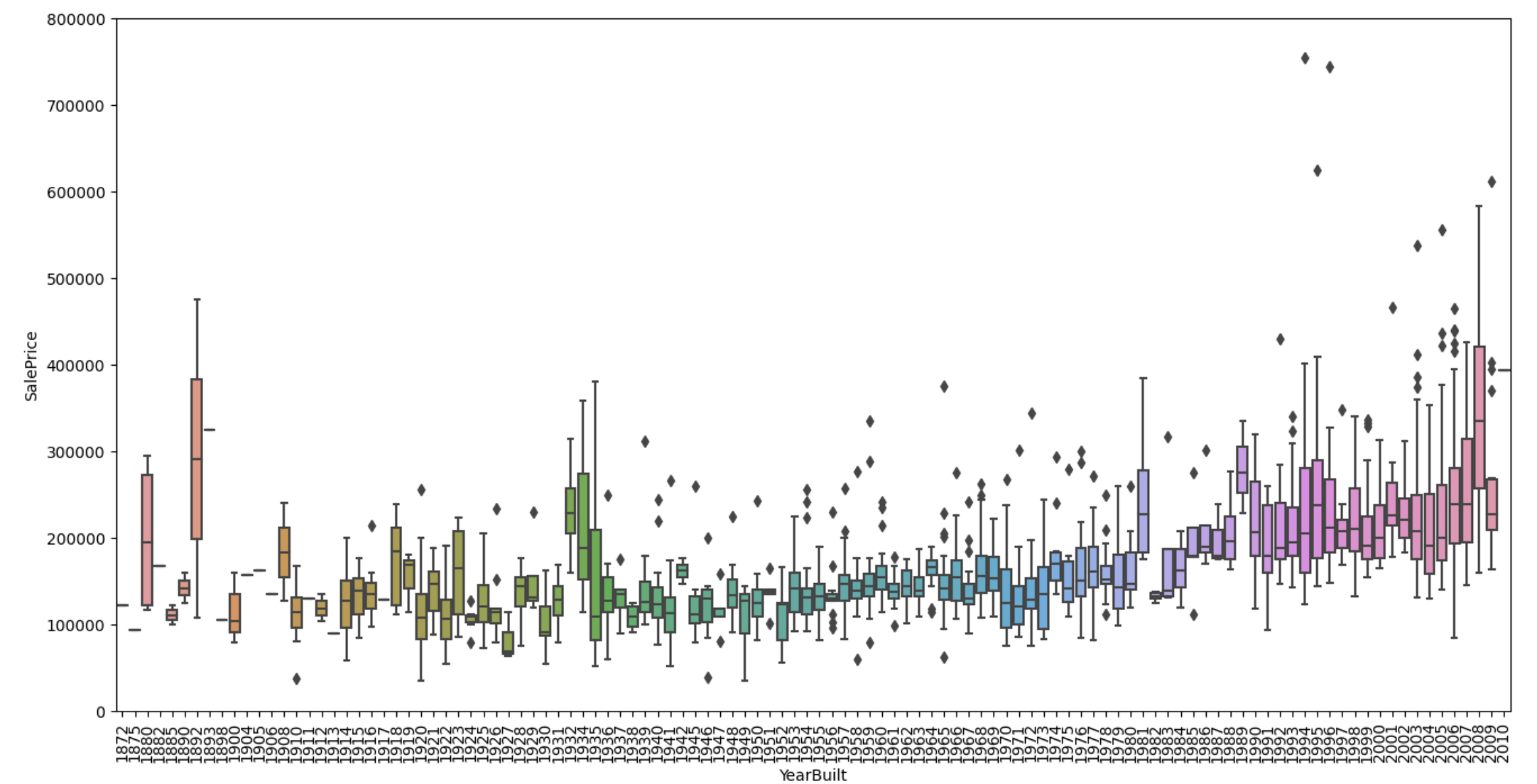
Part.2의 마지막으로 년도별 판매가격의 연관성을 시각화 하였습니다.
오래된 건물보다는 새로지은 건물들에 돈을 더 많이 쓰는 경향이 보입니다.
Part.2의 결론으로는
- GriLivArea와 TotalBsmtSF는 SalePrice와 선형관계인 것을 확인할 수 있습니다. 모두 양의 관계를 나타내며, 한 변수가 증가할수록 다른 변수도 증가하는 모습을 보입니다.TotalBsmtSF는 조금 더 기울기가 높아지는 것을 확인할 수 있습니다.
- OveraQual와 YearBuilt도 SalePrice와 연관성을 보입니다. box plot을 통해서 품질에 따른 상승도를 보여주었습니다.
분석해야할 변수들은 많지만 Part.2에서는 4가지 변수만 분석해보았습니다.
Part.3부터는 다음 포스팅으로 찾아뵙도록 하겠습니다.

'Python > Kaggle' 카테고리의 다른 글
| [Kaggle] 집 값을 예측해보자- House Prices - Advanced Regression Techniques[2] (3) | 2023.12.28 |
|---|---|
| [Kaggle] Titanic Tutorial - 캐글을 시작해보자! (2) | 2023.12.20 |
| [Kaggle] Kaggle이란 무엇인가?! (3) | 2023.12.11 |


