안녕하세요. 위기의 코딩맨입니다.
오늘은 Databricks를 이용하여 캐글의 Titanic Data를 이용하여
Data를 시각화 하는 방법에 대해서 알아보도록 하겠습니다.
먼저 데이터를 받아보도록 하겠습니다.
캐글 홈페이지에 접속해서 로그인 하신 후, competitions에 들어가셔서 밑에 Titanic을 클릭해주세요.
[ Kaggle ]

Data 탭으로 이동하시면 밑에 gender_su...test...train... 데이터들을 다운 받도록 합니다.
[ Databicks ]
Data Import를 통해서 다운 받은 데이터를 저장해야합니다.


해당 데이터는 "/FileStore/tables/파일명"으로 경로가 설정됩니다.
이제 코드로 한번 데이터가 잘 들어왔는지 보도록 하겠습니다.
titanic_spark_data = spark.read.csv('/FileStore/tables/titanic_train.csv', header=True, inferSchema=True)
titanic_spark_data.limit(10)
해당 코드는 spark를 이용해서 csv 파일을 읽어 titanic_spark_data에 저장하는 코드입니다.
경로는 위에 업로드한 파일경로를 입력하시면 됩니다.
결과를 확인해보시면 limit(10)을 통해서 10개만 데이터를 가져온 것을 확인하실 수 있습니다. (Showing all 10 rows.)

데이터가 잘 들어온 것을 확인할 수 있습니다.
이제 해당 데이터를 그래프 등 시각화 하는 방법을 알아보도록 하겠습니다.
해당 결과를 Display() 함수를 적용해서 출력하면 시각화를 사용하실 수 있습니다.
display() 함수를 적용하지 않으면 해당 결과를 출력되지만

해당 display()함수를 적용하게되면 밑에 표, 바와 같이 생긴 버튼이 생성됩니다.

바 처럼 생긴 버튼을 클릭하게 되면 해당 결과를 확인할 수 있습니다.
남성과 여성의 수를 바 그래프를 통해서 결과를 볼 수 있습니다.
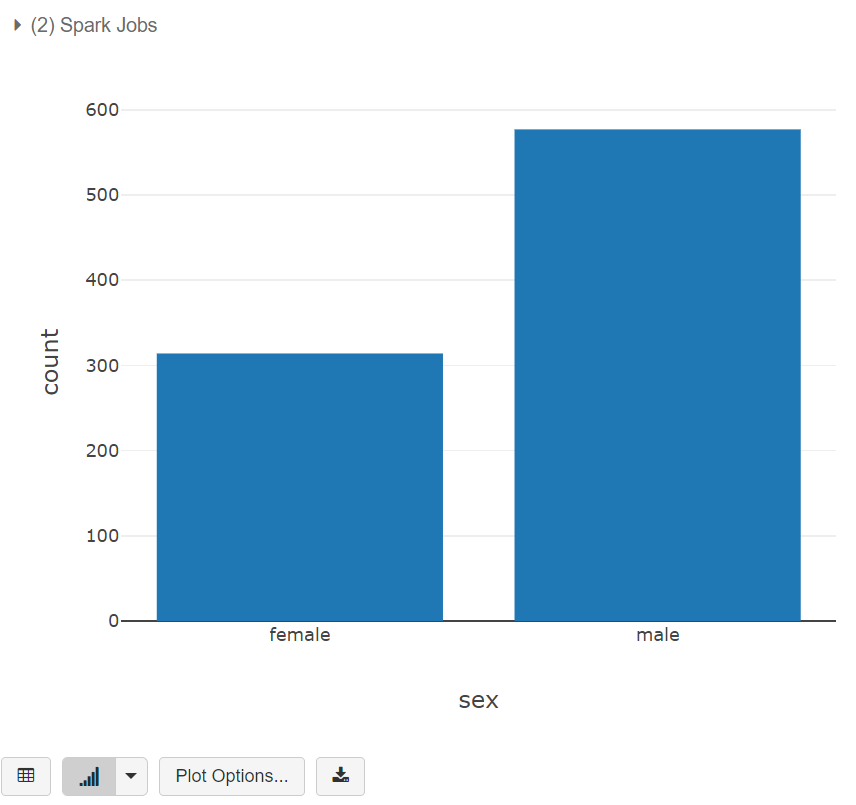
이제 더 나아가서
성별 기준으로 살아남은 사람과 살아남지 못한 사람의 데이터를 시각화 해보겠습니다.
import pyspark.sql.functions as F
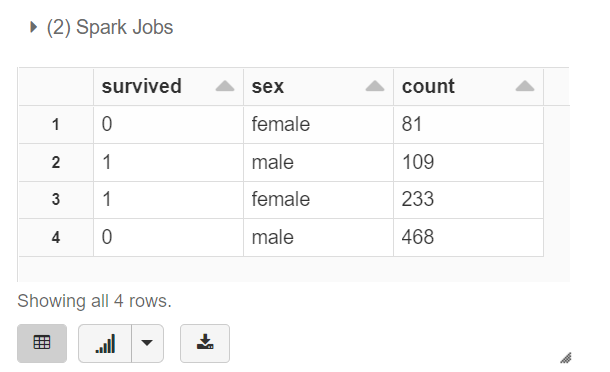
display(titanic_spark_data.groupBy(F.col('survived'), F.col('sex')).count())
groupBy를 통해서 survived, sex를 기준으로 잡고 그에 해당하는 수를 불러오도록 진행했습니다.
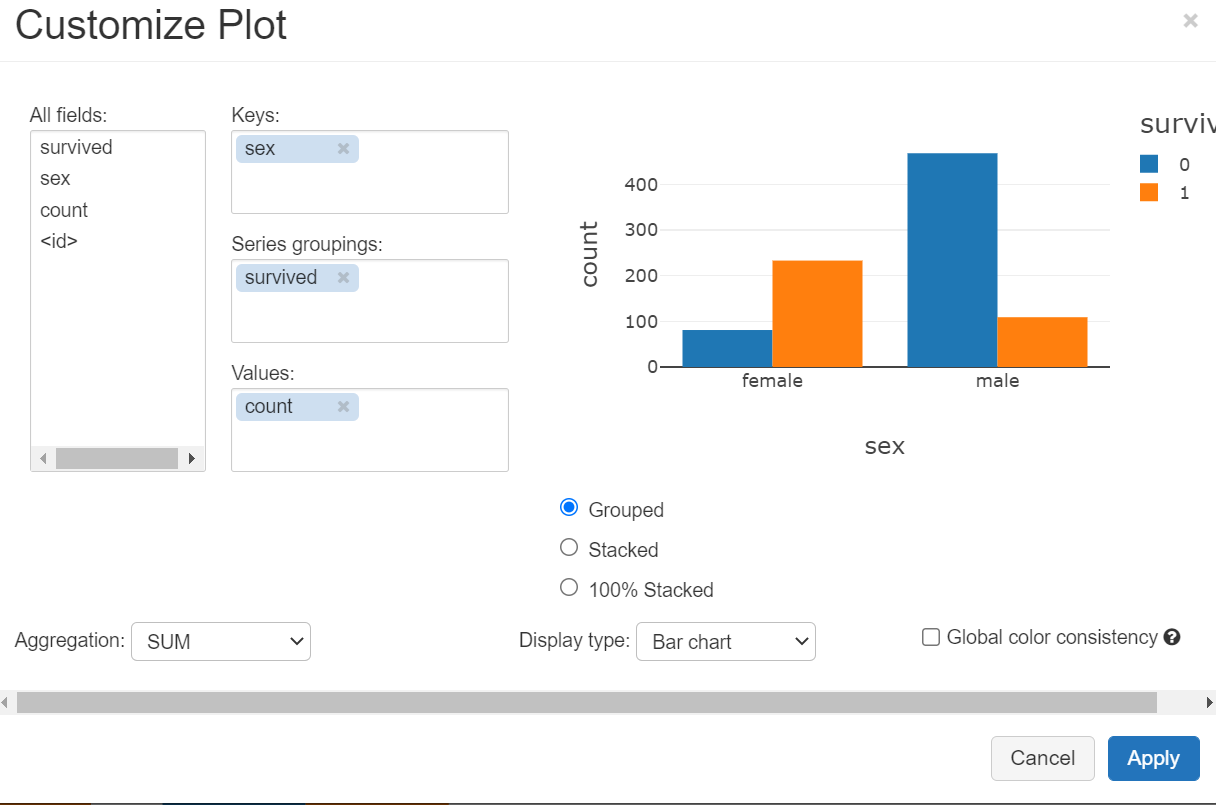
sex를 기준으로 잡고 survived를 그룹핑을 진행, Values에 Count 값을 넣어주어 그래프를 완성했습니다.

오늘은 간단하게 Databricks를 이용하여 TItanic의 데이터를 간단하게 시각화하는 방법을 알아보았습니다.
사용할 수록 재밌는 것 같네요!
'Spark' 카테고리의 다른 글
| [We-Co] Pyspark Xgboost - Spark, MLlib Pipelines, 수요 예측 (8) | 2022.03.15 |
|---|---|
| [We-Co] Spark - ML PipeLine 예제 (1) | 2022.03.10 |
| [We-Co] Databricks Community Edition - Spark (1) | 2022.02.28 |
| [We-Co] Spark Tokenizer - 문자열나누기 (0) | 2021.09.29 |
| [We-Co] Spark MLlib - Pipeline, Logistic Regression (0) | 2021.09.28 |


