반응형
안녕하세요. 위기의 코딩맨입니다.
요즘 하루하루 너무 빠르게 지나가고 있는게 너무나도 느껴지고 있습니다..
벌써 6주차라니.. 너무 빠르잖아..!!

6주차에서는 기본적인 용어와 학습에 대한 흐름을 배웠습니다.
6주차 내용을 정리해보도록 하겠습니다.
[ 6주차 학습내용 ]
딥러닝 필요한 조건(능력)
- 수학
- TOOLS(텐서플로, 파이토치)
- 논문
인공지능 정의 - 사람의 지능을 컴퓨터로 수학적으로 모방하는 것으로 생각하시면 될것같습니다.
인공지능 > 머신러닝 > 딥러닝

딥러닝의 역사
- 2012 - AlexNet
- 2013 - DQN
- 2014 - Encoder/Decoder, Adam
- 2015 - GAN, ResNet
- 2016 - -
- 2017 - Transformer
- 2018 - Bert
- 2019 - Big Language Models (GPT-X)
- 2020 - Self-Supervised Learning
딥러닝의 중요한 키 포인트
- Data - Classification, Segmentation, Detection, Pose Estimation, Visual QnA
- 학습하고자하는 Model - AlexNet, GoogleNet, LSTM ….
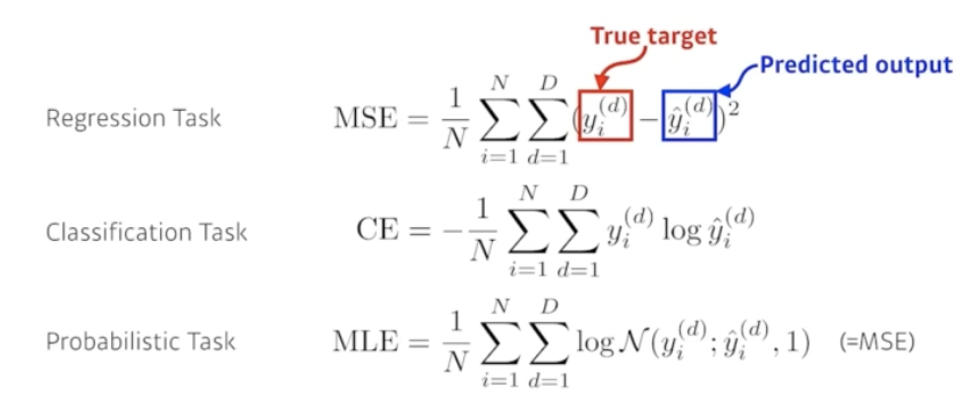
- Loss Function - Regression Task = MSE, Classification Task = CE, Probabilistic Task = MLE
- Algorithm - Optimization 종류
Neural Networks - 뇌 신경망을 모방하여 수학적으로 만들어낸 방법론
선형회귀 (Linear Neural Nettworks )
- Loss 를 줄어들이는 것이 목표
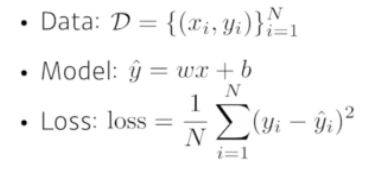
- w,b를 지속적으로 계산하여 업데이트
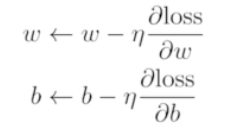 |
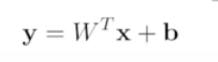 |
Beyond Linear Neural Networks
- ReLU
- Sigmoid
- Hyperbolic Tangent
Loss 종류와 공식
최적화의 주요 용어 ( Optimization )
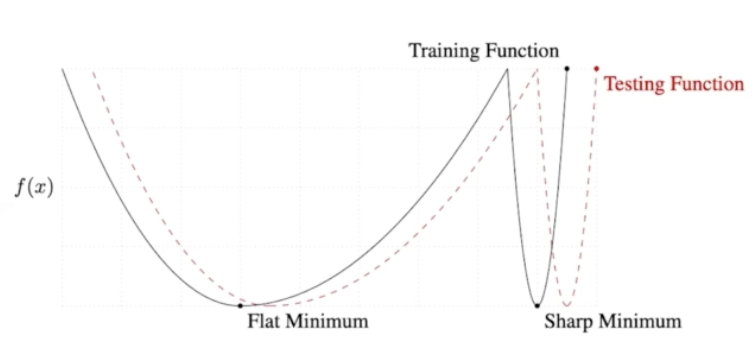
- Generalization - 일반화 성능을 높이는 목적 Training Error와 Test Error와 차이 값
- Under-fitting - 학습 데이터가 부족하여 충분히 학습이 되지 않은 상태
- Over-fitting - 너무 학습을 진행하여 모든 데이터를 나눠지는 것
- Cross Validation - 학습 데이터의 기준을 나누는 것 (최적의 하이퍼파라미터를 생성)
- Bias-variance tradeoff
- Booststrapping - 통계학 관련, 학습 데이터 중, 몇개만 활용하는 것을 의미
- Bagging - 샘플을 여러번뽑아서 모델을 학습시켜 결과물을 집계하는 방식
- Boostring - 가중치를 활용, 약 분류기를 강 분류기로 만드는 방식
Gradient Descent - 1차 미분한 값을 반복적으로 업데이트 시켜서 목적을 달성
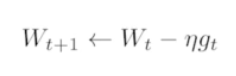
- Batch-size Matters - 큰 배치를 활용하게되면 Flat Minimizers가 발생
- Momentum - 한쪽 방향으로 흘렀을때, 약간의 데이터를 활용
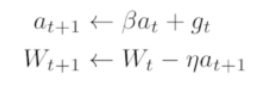
- Adagrad - 변화가 큰 것들은 변화를 줄이고 변화가 작은것은 변화를 크게! G가 변화값, G의 값이 계속 적으로 커져서 뒤로 갈수록 학습이 멈춤
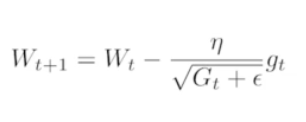
- Adadelta - no learning late
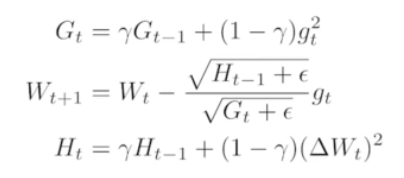
- RMSprop
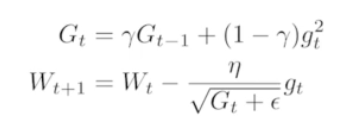
- Adam
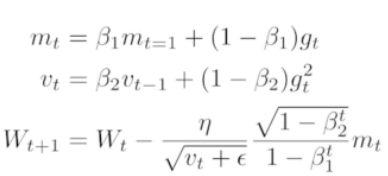
Regularization
- Early Stopping - Loss가 커질때 학습을 중간에 멈춤
- Parameter Norm Penalty - 합이 어느 정도 커지면 학습을 멈춤
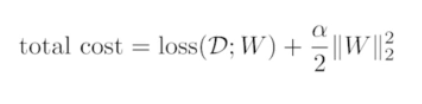
- Data Augmentation - 데이터가 많을수록 학습이 잘되는 경우가 많음, 주어진 데이터를 각도, 색상 크기를 변경하며 데이터를 생성
- Noise Robustness - 입력데이터에 노이즈를 넣어서 데이터를 생성하고 학습을 진행하면 결과가 좋음
- Label Smoothing - 데이터 2개를 뽑아서 서로 섞어서. 학습을 진행
- DropOut - 일부 뉴런을 제거하여 학습을 용이하게 진행하는 방법
- Batch Normalization - 레이어가 많을 경우, 퓨처 값을 줄어드는 효과가 생김
그리고 6주차는 코드 제출이 2가지 문제가 있습니다.
난이도는 어렵지 않으나..
기초적인 흐름을 잘 익힐수 있는 문제였던것 같습니다. 흐흐

- 본 포스트의 학습 내용은 부스트클래스 <AI 엔지니어 기초 다지기 : 부스트캠프 AI Tech 준비과정> 강의 내용을 바탕으로 작성되었습니다
반응형
'[부스트캠프 AI Tech 준비과정] 2회차' 카테고리의 다른 글
| [부스트캠프 AI Tech 준비과정] - 수료 (2) | 2024.06.17 |
|---|---|
| [부스트캠프 AI Tech 준비과정] 7주차 - RNN, Transformer, GAN (0) | 2024.06.07 |
| [부스트캠프 AI Tech 준비과정] - 5주차 인공지능 수학 2 (2) | 2024.05.23 |
| [부스트캠프 AI Tech 준비과정] - 4주차 인공지능 수학 (0) | 2024.05.17 |
| [부스트캠프 AI Tech 준비과정] - 3주차 (1) | 2024.05.13 |



