안녕하세요. 위기의 코딩맨입니다.
저번에 BERT의 SQuAD Dataset에 대해서 알아보았습니다.
[We-Co] SQuAD Dataset - Tensorflow, NLP, Transformer
안녕하세요. 위기의 코딩맨입니다. 오늘은 BERT를 기반으로 사용하는 SQuAD Dataset에 대해서 간단하게 알아보고 구현해보도록 하겠습니다. BERT에 대해서 궁금하시면 BERT [We-Co] BERT - 자연어처리, NLP
we-co.tistory.com
SQuAD Data는 영어로된 데이터 셋을 갖고있지만
SQuAD Data의 한국어 버전인 KorQuAD 사용하여 질문에 대한 답변을 예측하는 모델을 작성해보도록 하겠습니다.
[ KorQuAD ]
KorQuAD를 사용하기 앞서서
simple transformers에 해당하는 라이브러리를 설치해야합니다.
사용할 Model의 기본 정보입니다.
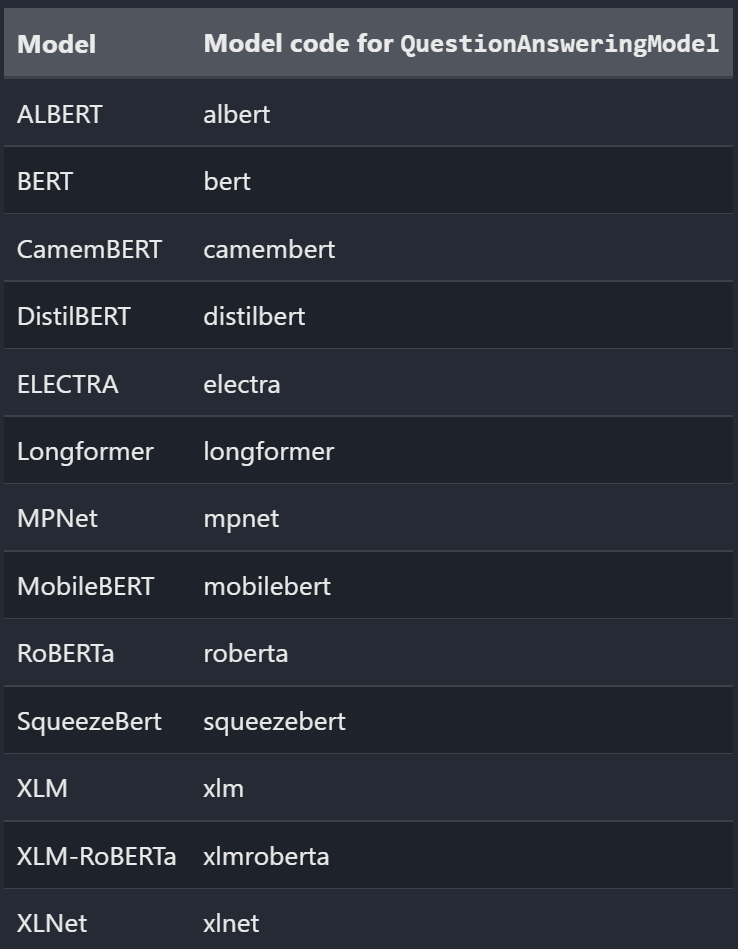
https://simpletransformers.ai/docs/qa-specifics/
Question Answering Specifics
Specific notes for Question Answering tasks.
simpletransformers.ai
https://github.com/ThilinaRajapakse/simpletransformers
GitHub - ThilinaRajapakse/simpletransformers: Transformers for Classification, NER, QA, Language Modelling, Language Generation,
Transformers for Classification, NER, QA, Language Modelling, Language Generation, T5, Multi-Modal, and Conversational AI - GitHub - ThilinaRajapakse/simpletransformers: Transformers for Classifica...
github.com
!pip install simpletransformers
그리고 Pre-Training 한 데이터는 Hugging Face의 데이터를 받아와서 진행하도록 하겠습니다.
https://huggingface.co/bert-base-multilingual-cased
bert-base-multilingual-cased · Hugging Face
📊 MKaan/multilingual-cpv-sector-classifier
huggingface.co
그리고 KorQuAD v1.0 데이터 다운로드(train, eval)를 다운받아 주도록 합니다.
!wget https://raw.githubusercontent.com/korquad/korquad.github.io/master/dataset/KorQuAD_v1.0_train.json -O KorQuAD_v1.0_train.json
!wget https://raw.githubusercontent.com/korquad/korquad.github.io/master/dataset/KorQuAD_v1.0_dev.json -O KorQuAD_v1.0_dev.json
받아온 데이터를 확인해보면
import json
with open('KorQuAD_v1.0_train.json', 'r') as f:
train_data = json.load(f)
train_data = [item for topic in train_data['data'] for item in topic['paragraphs'] ]
print(train_data)

9681개의 데이터가 들어있는 것을 확인할 수 있습니다.
데이터의 정보는 해당 링크에서 더욱 자세하게 확인하실 수 있습니다.
https://simpletransformers.ai/docs/qa-data-formats/
Question Answering Data Formats
Data Formats for Question Answering tasks.
simpletransformers.ai
빠른 학습을 위해 일부만 Training data로 설정합니다.
1000개만 사용합니다.
using_num_sample = 1000
train_data = train_data[:using_num_sample]
다음으로 처음에 다운받았던 라이브러리를 사용하기 위해 import를 진행합니다.
그리고 bascConfig 레벨을 설정해주도록 하고 해당 정보를 토대로 배치 사이즈를 정해주도록 합니다.
import logging
from simpletransformers.question_answering import QuestionAnsweringModel, QuestionAnsweringArgs
logging.basicConfig(level=logging.INFO)
transformers_logger = logging.getLogger("transformers")
transformers_logger.setLevel(logging.WARNING)
model_args = QuestionAnsweringArgs()
model_args.train_batch_size = 64
그리고 Hugging Face에서 제공되는 MultiLang BERT를 다운받아 줍니다.
model = QuestionAnsweringModel(
"bert", "bert-base-multilingual-cased", args=model_args
)
Train Data를 모델에 적용해주도록 합니다.
num_train_epochs가 기본 값이 1로 설정되어 있어, 1번의 Epoch이 실행됩니다.
model.train_model(train_data)


이제 Fine-Turning이 끝난 데이터를 사용하면 됩니다.
그리고 아까 설치한 dev 데이터를 불러옵니다.
with open('KorQuAD_v1.0_dev.json', 'r') as f:
dev_data = json.load(f)
dev_data = [item for topic in dev_data['data'] for item in topic['paragraphs'] ]

다음으로 prediction을 수행해 주도록 합니다.
preds = model.predict(dev_data)
예측 결과와 비교하기 위해 다시 기존의 데이터를 불러와 줍니다.
with open('KorQuAD_v1.0_dev.json', 'r') as f:
gt_data = json.load(f)
gt_data = [item for topic in gt_data['data'] for item in topic['paragraphs'] ]
결과를 확인해보면
gt_data[0]['context']
1989년 2월 15일 여의도 농민 폭력 시위를 주도한 혐의(폭력행위등처벌에관한법률위반)으로 지명수배되었다. 1989년 3월 12일 서울지방검찰청 공안부는 임종석의 사전구속영장을 발부받았다. 같은 해 6월 30일 평양축전에 임수경을 대표로 파견하여 국가보안법위반 혐의가 추가되었다. 경찰은 12월 18일~20일 사이 서울 경희대학교에서 임종석이 성명 발표를 추진하고 있다는 첩보를 입수했고, 12월 18일 오전 7시 40분 경 가스총과 전자봉으로 무장한 특공조 및 대공과 직원 12명 등 22명의 사복 경찰을 승용차 8대에 나누어 경희대학교에 투입했다. 1989년 12월 18일 오전 8시 15분 경 서울청량리경찰서는 호위 학생 5명과 함께 경희대학교 학생회관 건물 계단을 내려오는 임종석을 발견, 검거해 구속을 집행했다. 임종석은 청량리경찰서에서 약 1시간 동안 조사를 받은 뒤 오전 9시 50분 경 서울 장안동의 서울지방경찰청 공안분실로 인계되었다.
해당 데이터가 들어있습니다.
질문의 데이터를 보고
gt_data[0]['qas'][0]['question']
임종석이 여의도 농민 폭력 시위를 주도한 혐의로 지명수배 된 날은?
답변을 보면
print('정답 :', gt_data[0]['qas'][0]['answers'][0]['text'])
print('예측한 답변 :', preds[0][0]['answer'][0])


오늘은 KorQuAD 를 사용하여 질문에 해당하는 답변을 예측하는 방법에 대해서 알아보았습니다.

'Python > Tensorflow' 카테고리의 다른 글
| [We-Co] ChatGPT, BARD의 차이점, 다른점이 무엇일까? (59) | 2023.06.20 |
|---|---|
| [We-Co] Python Ai 얼굴인식 모델 및 구현 (14) | 2023.05.15 |
| [We-Co] SQuAD Dataset - Tensorflow, NLP, Transformer (4) | 2022.02.16 |
| [We-Co] BERT - 자연어처리, NLP (0) | 2022.02.11 |
| [We-Co] Transformer - 포르투갈어를 영어로 변역 Part.2 (0) | 2022.02.10 |



