안녕하세요. 위기의 코딩맨입니다.
오늘은 Tensorflow의 공식 문서와 현재 듣고있는 강의를 토대로
포르투갈어를 영어로 변역하는 모델을 작성해보도록 하겠습니다.
https://www.tensorflow.org/text/tutorials/transformer
언어 이해를 위한 변환기 모델 | Text | TensorFlow
도움말 Kaggle에 TensorFlow과 그레이트 배리어 리프 (Great Barrier Reef)를 보호하기 도전에 참여 이 페이지는 Cloud Translation API를 통해 번역되었습니다. Switch to English 언어 이해를 위한 변환기 모델 이 튜
www.tensorflow.org
먼저 사용할 라이브러리를 설치해주도록 합니다.
저는 코랩환경을 사용하기 때문에 앞에 !를 붙여서 사용했습니다.
examples, metadata = tfds.load('ted_hrlr_translate/pt_to_en', with_info=True,
as_supervised=True)
train_examples, val_examples = examples['train'], examples['validation']
다운받은 Dataset에서 테스트로 3개의 데이터를 확인해보도록 하겠습니다.
for pt_examples, en_examples in train_examples.batch(3).take(1):
for pt in pt_examples.numpy():
print(pt.decode('utf-8'))
print()
for en in en_examples.numpy():
print(en.decode('utf-8'))
e quando melhoramos a procura , tiramos a única vantagem da impressão , que é a serendipidade .
mas e se estes fatores fossem ativos ?
mas eles não tinham a curiosidade de me testar .
and when you improve searchability , you actually take away the one advantage of print , which is serendipity .
but what if it were active ?
but they did n't test for curiosity .
텍스트 토큰화 작업을 진행합니다.
텍스트를 직접 모델을 해결할 수 없으므로 숫자로 표현하기위해 변환하는 작업을 의미합니다.
saved_model 을 다운로드하고 압축을 풀고 가져옵니다.
model_name = "ted_hrlr_translate_pt_en_converter"
tf.keras.utils.get_file(
f"{model_name}.zip",
f"https://storage.googleapis.com/download.tensorflow.org/models/{model_name}.zip",
cache_dir='.', cache_subdir='', extract=True
)
tokenizers = tf.saved_model.load(model_name)
[item for item in dir(tokenizers.en) if not item.startswith('_')]
tokensizers는 tf.save_mdel에 두개의 텍스트 토크나이저가 포함되어 있다고합니다. 하나는 영어, 하나는 포루투갈어용
tokenizers 목록으로는 8개의 함수를 포함하고 있습니다.
['detokenize',
'get_reserved_tokens',
'get_vocab_path',
'get_vocab_size',
'lookup',
'tokenize',
'tokenizer',
'vocab']
다운받은 모델로 토크나이즈 테스트 해보도록 하겠습니다.
for en in en_examples.numpy():
print(en.decode('utf-8'))
and when you improve searchability , you actually take away the one advantage of print , which is serendipity .
but what if it were active ?
but they did n't test for curiosity .
encoded = tokenizers.en.tokenize(en_examples)
for row in encoded.to_list():
print(row)
[2, 72, 117, 79, 1259, 1491, 2362, 13, 79, 150, 184, 311, 71, 103, 2308, 74, 2679, 13, 148, 80, 55, 4840, 1434, 2423, 540, 15, 3]
[2, 87, 90, 107, 76, 129, 1852, 30, 3]
[2, 87, 83, 149, 50, 9, 56, 664, 85, 2512, 15, 3]
위에 코드들은 사람이 읽는 언어를 토큰 ID로 변경한 모습이고
앞으로 작성하는 코드는 반대로 토큰 ID를 언어로 변경하는 작업입니다.
encoded에 토큰 ID가 들어가있고 그 해당 토큰들을 다시 decode로 변환하여 출력합니다.
round_trip = tokenizers.en.detokenize(encoded)
for line in round_trip.numpy():
print(line.decode('utf-8'))
and when you improve searchability , you actually take away the one advantage of print , which is serendipity .
but what if it were active ?
but they did n ' t test for curiosity .
해당 코드는 토큰 ID에서 토큰 텍스트로 변환하는 작업입니다.
lookpu 함수를 사용하여 작업한 모습이며, [START], [END]가 포함되어 있는것을 확인할 수 있습니다.
tokens = tokenizers.en.lookup(encoded)
tokens
<tf.RaggedTensor [[b'[START]', b'and', b'when', b'you', b'improve', b'search', b'##ability',
b',', b'you', b'actually', b'take', b'away', b'the', b'one', b'advantage',
b'of', b'print', b',', b'which', b'is', b's', b'##ere', b'##nd', b'##ip',
b'##ity', b'.', b'[END]'] ,
[b'[START]', b'but', b'what', b'if', b'it', b'were', b'active', b'?',
b'[END]'] ,
[b'[START]', b'but', b'they', b'did', b'n', b"'", b't', b'test', b'for',
b'curiosity', b'.', b'[END]']
다음으로 파이프라인을 구축하기 위해 Data set에 몇가지 변환을 적용해야합니다.
def tokenize_pairs(pt, en):
pt = tokenizers.pt.tokenize(pt)
pt = pt.to_tensor()
en = tokenizers.en.tokenize(en)
en = en.to_tensor()
return pt, en
버퍼 사이즈와 배치 사이즈를 적용을 해야합니다.
BUFFER_SIZE = 20000
BATCH_SIZE = 64
설정한 버퍼사이즈와 배치 사이즈를 데이터에 적용합니다.
def make_batches(ds):
return (
ds
.cache()
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE)
.map(tokenize_pairs, num_parallel_calls=tf.data.AUTOTUNE)
.prefetch(tf.data.AUTOTUNE))
train_batches = make_batches(train_examples)
val_batches = make_batches(val_examples)
전에 블로그 작성에서 Transformer 부분에서 위치 인코딩 공식을 코드로 작성해야 합니다.
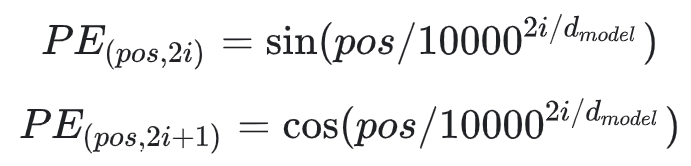
def get_angles(pos, i, d_model):
angle_rates = 1 / np.power(10000, (2 * (i//2)) / np.float32(d_model))
return pos * angle_rates
다음으로 Positional Encoding 함수
def positional_encoding(position, d_model):
angle_rads = get_angles(np.arange(position)[:, np.newaxis],
np.arange(d_model)[np.newaxis, :],
d_model)
# apply sin to even indices in the array; 2i
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])
# apply cos to odd indices in the array; 2i+1
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])
pos_encoding = angle_rads[np.newaxis, ...]
return tf.cast(pos_encoding, dtype=tf.float32)
적용된 Positional Encoding 확인해보겠습니다.
n, d = 2048, 512
pos_encoding = positional_encoding(n, d)
print(pos_encoding.shape)
pos_encoding = pos_encoding[0]
# Juggle the dimensions for the plot
pos_encoding = tf.reshape(pos_encoding, (n, d//2, 2))
pos_encoding = tf.transpose(pos_encoding, (2, 1, 0))
pos_encoding = tf.reshape(pos_encoding, (d, n))
plt.pcolormesh(pos_encoding, cmap='RdBu')
plt.ylabel('Depth')
plt.xlabel('Position')
plt.colorbar()
plt.show()
(1, 2048, 512)
다음은 마스킹 부분을 알아보도록 하겠습니다.
텍스트가 포함되어있는지 확인하는 작업으로, 시퀀스 배치에 모든 패드 토큰을 마스킹을 진행합니다.
모델이 패딩을 입력으로 취급하는 것을 막기 위함이라고 합니다.
마스크는 패드 값 0이 있는 위치를 나타내며, 위치에는 1, 아니면 0을 출력합니다.
def create_padding_mask(seq):
seq = tf.cast(tf.math.equal(seq, 0), tf.float32)
# add extra dimensions to add the padding
# to the attention logits.
return seq[:, tf.newaxis, tf.newaxis, :] # (batch_size, 1, 1, seq_len)
마스킹 테스트를 진행해보면
첫번째 2,3에 0이 들어있으므로 2,3에 1,1이 들어가는 것을 확인할 수 있습니다.
두번째 3,4에 0이 들어있으므로 3,4에 1,1이 들어가는 것을 확인할 수 있습니다.
마지막은 0,1,2에 0이 들어가있으므로 0,1,2에 1,1,1이 들어가는 것을 확인할 수 있습니다.
x = tf.constant([[7, 6, 0, 0, 1], [1, 2, 3, 0, 0], [0, 0, 0, 4, 5]])
create_padding_mask(x)
<tf.Tensor: shape=(3, 1, 1, 5), dtype=float32, numpy=
array([[[[0., 0., 1., 1., 0.]]],
[[[0., 0., 0., 1., 1.]]],
[[[1., 1., 1., 0., 0.]]]], dtype=float32)>미리보기 마스크는 시퀀스에서 미래 토큰을 마스킹하는데 사용이 된다고합니다.
예를들어 3번째 토큰을 예측하기 위해서 1번째, 2번째 토큰을 사용을 사용하고
4번째 토큰은 1,2,3번째 토큰을 사용하는 것입니다.
def create_look_ahead_mask(size):
mask = 1 - tf.linalg.band_part(tf.ones((size, size)), -1, 0)
return mask
테스트를 진행해보면
x = tf.random.uniform((1, 3))
temp = create_look_ahead_mask(x.shape[1])
temp
<tf.Tensor: shape=(3, 3), dtype=float32, numpy=
array([[0., 1., 1.],
[0., 0., 1.],
[0., 0., 0.]], dtype=float32)>
Scaled Dot-Product Attention 코드를 알아보도록 하겠습니다.
어텐션 기능은 Q, K, V의 3개의 입력을 받습니다.
def scaled_dot_product_attention(q, k, v, mask):
matmul_qk = tf.matmul(q, k, transpose_b=True)
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
if mask is not None:
scaled_attention_logits += (mask * -1e9)
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1)
output = tf.matmul(attention_weights, v)
return output, attention_weights
def print_out(q, k, v):
temp_out, temp_attn = scaled_dot_product_attention(
q, k, v, None)
print('Attention weights are:')
print(temp_attn)
print('Output is:')
print(temp_out)
np.set_printoptions(suppress=True)
temp_k = tf.constant([[10, 0, 0],
[0, 10, 0],
[0, 0, 10],
[0, 0, 10]], dtype=tf.float32) # (4, 3)
temp_v = tf.constant([[1, 0],
[10, 0],
[100, 5],
[1000, 6]], dtype=tf.float32) # (4, 2)
[0,10,0]을 Q로 입력하고 K는 Q의 입력을 받아 해당하는 1번쨰 인자인 [0,10,0]을 선택하게되고
K를 바탕으로 V를 계산하게되면 [10,0]이 나오게 됩니다.
temp_q = tf.constant([[0, 10, 0]], dtype=tf.float32)
print_out(temp_q, temp_k, temp_v)
Attention weights are:
tf.Tensor([[0. 1. 0. 0.]], shape=(1, 4), dtype=float32)
Output is:
tf.Tensor([[10. 0.]], shape=(1, 2), dtype=float32)
[0, 0, 10]을 인자로 받고 2,3번째 인자가 선택되고, 1을 2개로 나누어 0.5, 0.5로 나뉘어 적용되고
그에 해당하는 평균 값으로 V가 출력되는 것을 확인할 수 있습니다.
temp_q = tf.constant([[0, 0, 10]], dtype=tf.float32) # (1, 3)
print_out(temp_q, temp_k, temp_v)
Attention weights are:
tf.Tensor([[0. 0. 0.5 0.5]], shape=(1, 4), dtype=float32)
Output is:
tf.Tensor([[550. 5.5]], shape=(1, 2), dtype=float32)Multi-Head-Attention부분의 함수를 코드로 나타내도록 하겠습니다.
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
self.depth = d_model // self.num_heads
self.wq = tf.keras.layers.Dense(d_model)
self.wk = tf.keras.layers.Dense(d_model)
self.wv = tf.keras.layers.Dense(d_model)
self.dense = tf.keras.layers.Dense(d_model)
def split_heads(self, x, batch_size):
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, v, k, q, mask):
batch_size = tf.shape(q)[0]
q = self.wq(q) # (batch_size, seq_len, d_model)
k = self.wk(k) # (batch_size, seq_len, d_model)
v = self.wv(v) # (batch_size, seq_len, d_model)
q = self.split_heads(q, batch_size) # (batch_size, num_heads, seq_len_q, depth)
k = self.split_heads(k, batch_size) # (batch_size, num_heads, seq_len_k, depth)
v = self.split_heads(v, batch_size) # (batch_size, num_heads, seq_len_v, depth)
scaled_attention, attention_weights = scaled_dot_product_attention(
q, k, v, mask)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3]) # (batch_size, seq_len_q, num_heads, depth)
concat_attention = tf.reshape(scaled_attention,
(batch_size, -1, self.d_model)) # (batch_size, seq_len_q, d_model)
output = self.dense(concat_attention) # (batch_size, seq_len_q, d_model)
return output, attention_weights
코드로 설정한 MultiHeadAttention을 테스트해보도록 합니다.
temp_mha = MultiHeadAttention(d_model=512, num_heads=8)
y = tf.random.uniform((1, 60, 512)) # (batch_size, encoder_sequence, d_model)
out, attn = temp_mha(y, k=y, q=y, mask=None)
out.shape, attn.shape
(TensorShape([1, 60, 512]), TensorShape([1, 8, 60, 60]))포인트 와이즈 피드포워드 네트워크 부분의 함수입니다.
사이에 ReLU 활성화가 있는 두 개의 완전히 연결된 레이어로 구성됩니다.
def point_wise_feed_forward_network(d_model, dff):
return tf.keras.Sequential([
tf.keras.layers.Dense(dff, activation='relu'), # (batch_size, seq_len, dff)
tf.keras.layers.Dense(d_model) # (batch_size, seq_len, d_model)
])
테스트를 진행해보면
sample_ffn = point_wise_feed_forward_network(512, 2048)
sample_ffn(tf.random.uniform((64, 50, 512))).shape
TensorShape([64, 50, 512])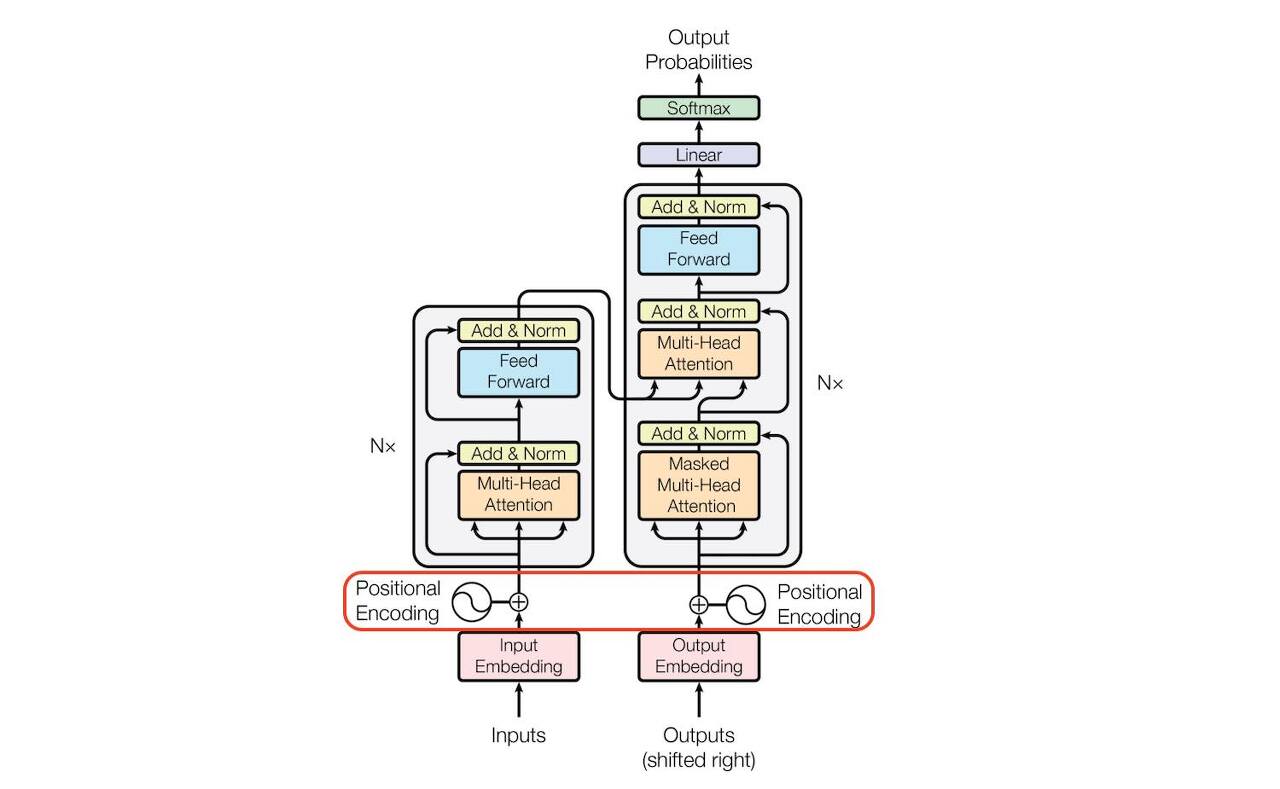
Part.1 부분에서는 Input Embedding, Positional Encoding,
Multi-Head Attention, Feed Forward, Mask의 부분을 작성하였습니다.
Part.2부분에서는 작성된 부분을 인코더, 디코더에서 사용하는 라인을 작성해보도록 하겠습니다.

[We-Co] Transformer - 포르투갈어를 영어로 변역 Part.2
안녕하세요. 위기의코딩맨입니다. 오늘은 포르투갈어를 영어로 변역 Part.2 부분을 알아보도록 하겠습니다. Part.1 [We-Co] Transformer - 포르투갈어를 영어로 변역 Part.1 안녕하세요. 위기의 코딩맨입니
we-co.tistory.com
'Python > Tensorflow' 카테고리의 다른 글
| [We-Co] BERT - 자연어처리, NLP (0) | 2022.02.11 |
|---|---|
| [We-Co] Transformer - 포르투갈어를 영어로 변역 Part.2 (0) | 2022.02.10 |
| [We-Co] Transformer - Tensorflow, NLP (0) | 2022.02.06 |
| [We-Co] word2vec - Tensorflow, 자연어처리 (0) | 2022.02.03 |
| [We-Co] NLP의 사용 분야와 용어 - 자연어 처리 (0) | 2022.01.28 |



