안녕하세요. 위기의 코딩맨입니다.
오늘은 Spark를 이요하여 문자를 count 하는 예제 한번 알아보겠습니다.
텍스트 파일 속에 있는 문자열 들을 Count 하기 위해 텍스트 파일을 하나 작성합니다.
[ 예제 ]
Spark를 실행하고..
해당 텍스트 파일을 inputfile로 지정해 주도록 합니다.
scala> val inputFile = sc.textFile("생성된텍스트파일경로/sparkTest.txt")

Split의 기준을 " "로 기준을 잡고 개수를 count 해주도록 기준을 설정해 주도록 합니다.
scala> val counts = inputFile.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_ + _);
scala> counts.cache()
해당 작업을 수행하고,
scala> counts.saveAsTextFile("작업완료경로/output")
작업이 완료된 output을 받기위한 경로를 설정합니다.
해당 경로로 이동해 DIR을 이용해 목록을 확인 할 수 있습니다.

해당 경로에서 type을 이용하여 part-00000와 part-00001 을 읽어보시면
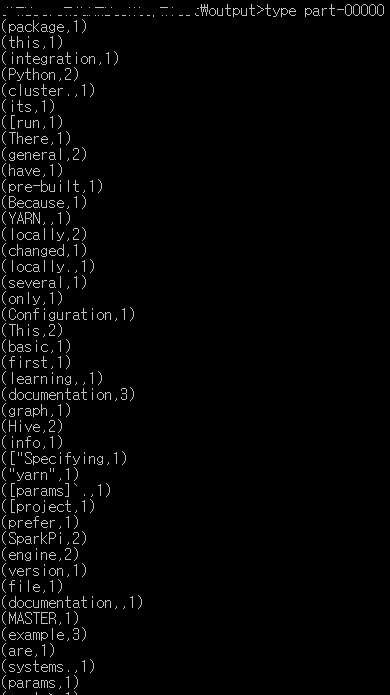
해당 텍스트 파일안에 있는 문자들을 " " 기준으로 Split하여 단어들이 몇개인지 Count한 결과가 들어있습니다.!
Spark를 실행하시고 loclahost:4040을 들어가보시면 상태 등을 확인할 수 있습니다.
아직은 잘 모르는 부분이라 설명은 넘어가도록 하겠습니다!
오늘은 WordCount 예제를 한번 풀어보았습니다.
아직 많이 부족한 부분도 많지만 천천히 하나씩 알아가보도록 하겠습니다.
'Spark' 카테고리의 다른 글
| [We-Co] groupBy(), groupByKey(), cogroup() - Spark (0) | 2021.08.24 |
|---|---|
| [We-Co] RDD 생성 (0) | 2021.08.11 |
| [We-Co] SparkContext (0) | 2021.08.11 |
| [We-Co] Spark RDD (0) | 2021.07.23 |
| [We-Co] Apache Spark (0) | 2021.07.23 |

